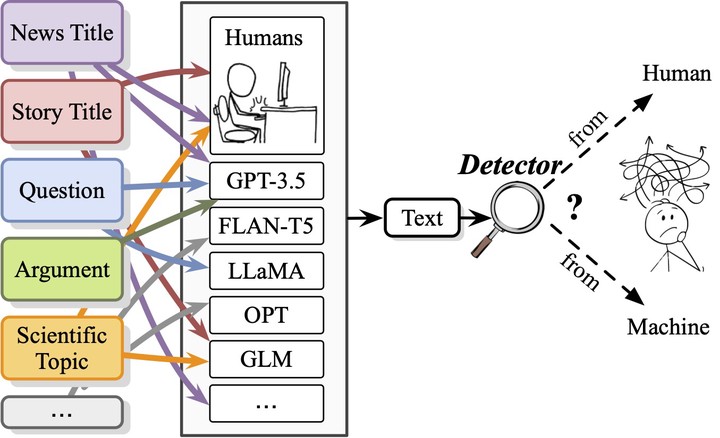
Abstract
Recent advances in large language models have enabled them to reach a level of text generation comparable to that of humans. These models show powerful capabilities across a wide range of content, including news article writing, story generation, and scientific writing. Such capability further narrows the gap between human-authored and machine-generated texts, highlighting the importance of deepfake text detection to avoid potential risks such as fake news propagation and plagiarism. However, previous work has been limited in that they testify methods on testbed of specific domains or certain language models. In practical scenarios, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a wild testbed by gathering texts from various human writings and deepfake texts generated by different LLMs. Human annotators are only slightly better than random guessing at identifying machine-generated texts. Empirical results on automatic detection methods further showcase the challenges of deepfake text detection in a wild testbed. In addition, out-of-distribution poses a greater challenge for a detector to be employed in realistic application scenarios.
Qintong Li
PhD student
My research interests are building machine learning models for open-ended text generation and commonsense reasoning.