GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers
Abstract
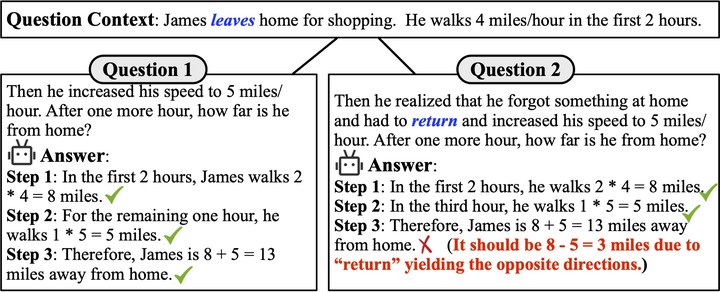
Large language models (LLMs) have achieved impressive performance across various mathematical reasoning benchmarks. However, there are increasing debates regarding whether these models truly understand and apply mathematical knowledge or merely rely on shortcuts for mathematical reasoning. One essential and frequently occurring evidence is that when the math questions are slightly changed, LLMs can behave incorrectly. This motivates us to evaluate the robustness of LLMs' math reasoning capability by testing a wide range of question variations. We introduce the adversarial grade school math (GSM-Plus) dataset, an extension of GSM8K augmented with various mathematical perturbations. Our experiments on 25 LLMs and 4 prompting techniques show that while LLMs exhibit different levels of math reasoning abilities, their performances are far from robust. In particular, even for problems that have been solved in GSM8K, LLMs can make mistakes when new statements are added or the question targets are altered. We also explore whether more robust performance can be achieved by composing existing prompting methods, in which we try an iterative method that generates and verifies each intermediate thought based on its reasoning goal and calculation result.
Qintong Li
PhD student
My research interests are building machine learning models for open-ended text generation and commonsense reasoning.