BBA: Bi-Modal Behavioral Alignment for Reasoning with Large Vision-Language Models
Abstract
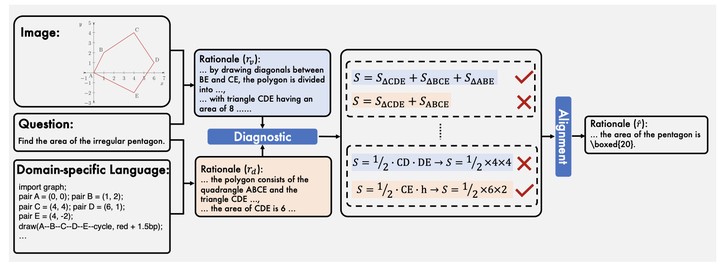
Multimodal reasoning stands as a pivotal capability for large vision-language models (LVLMs). The integration with Domain-Specific Languages (DSL), offering precise visual representations, equips these models with the opportunity to execute more accurate reasoning in complex and professional domains. However, the vanilla Chain-of-Thought (CoT) prompting method faces challenges in effectively leveraging the unique strengths of visual and DSL representations, primarily due to their differing reasoning mechanisms. Additionally, it often falls short in addressing critical steps in multi-step reasoning tasks. To mitigate these challenges, we introduce the Bi-Modal Behavioral Alignment (BBA) prompting method, designed to maximize the potential of DSL in augmenting complex multi-modal reasoning tasks. This method initiates by guiding LVLMs to create separate reasoning chains for visual and DSL representations. Subsequently, it aligns these chains by addressing any inconsistencies, thus achieving a cohesive integration of behaviors from different modalities. Our experiments demonstrate that BBA substantially improves the performance of GPT-4V(ision) on geometry problem solving (28.34%→34.22%), chess positional advantage prediction (42.08%→46.99%) and molecular property prediction (77.47%→83.52%).
Qintong Li
PhD student
My research interests are building machine learning models for open-ended text generation and commonsense reasoning.